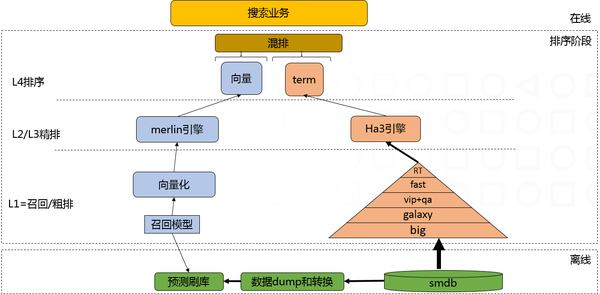
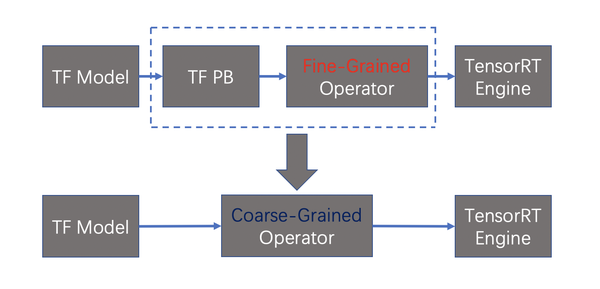
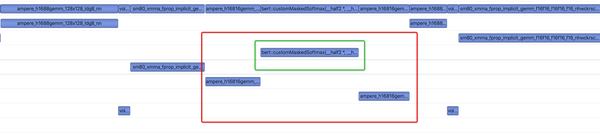
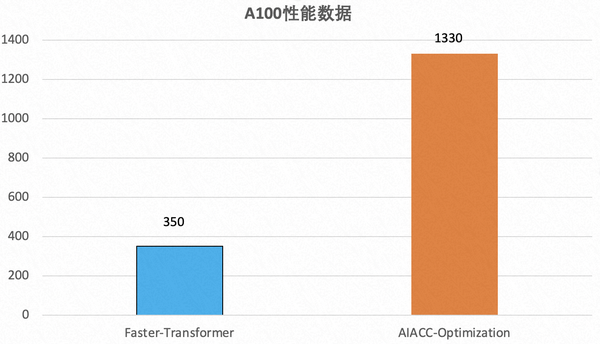
在把QTC模型映射到TensorRT并对齐精度的过程中,我们还遇到了其他一系列大大小小的其他问题,这里不一一展开,只在简单列举一下,包括用shuffle替换reduce来提高实现reshape的运算的效率,用identity层来实现data type cast的逻辑,conv层的参数转换,pooling的padding处理,reshape后接FC层参数排布等问题。
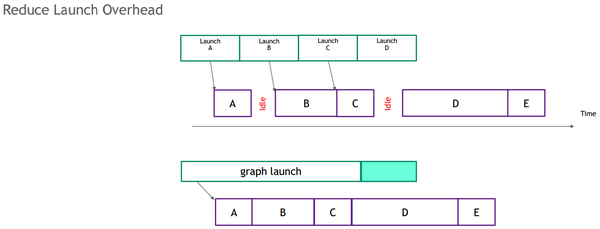
CUDA Graph是一个把所有kernel算子结合(capture)成Graph,然后整体launch这个Graph,减少频繁的kernel launch来带的开销以及kernel中间的gap。下图是普通的kernel执行和Graph执行的区别。可以看出,在kernel执行时因为需要CPU和GPU切换,造成小算子间会有比较大的GPU idle时间(gap引起),同时如果小算子执行的时间比较短,那么launch的时间占比就成了大头,造成GPU利用率低下。


 发表于 2022-9-21 16:18:34
发表于 2022-9-21 16:18:34